
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
Tags
- 스마트팜
- minikube
- 인공지능융합대학원
- 온실
- 정보과학대학원
- 쿠베플로우
- 미니쿠베
- 머신러닝
- Greenhouse
- 석사
- Nvidia Docker
- NVIDIA driver
- 인공지능
- 정보통신대학원
- 면접
- 파트타임
- 숭실대학교
- docker
- 야간대학원
- 특수대학원
- kubeflow
- 논문리뷰
- 딥러닝
- 국민대학교 대학원
- 엔비디아 도커
- mobaxterm
- 소프트웨어융합대학원
- 강화학습
- 면접 후기
- 도커
Archives
- Today
- Total
몰입과 소통
Reinforcement Learning Versus Model Predictive Control on Greenhouse Climate Control 본문
인공지능/논문 리뷰
Reinforcement Learning Versus Model Predictive Control on Greenhouse Climate Control
Dev Teddy 2024. 5. 20. 20:40URL : https://arxiv.org/abs/2303.06110
Reinforcement Learning Versus Model Predictive Control on Greenhouse Climate Control
Greenhouse is an important protected horticulture system for feeding the world with enough fresh food. However, to maintain an ideal growing climate in a greenhouse requires resources and operational costs. In order to achieve economical and sustainable cr
arxiv.org
ABSTRACT
- 온실 내 작물의 생장을 위해 효율적인 온실 생산의 기후 제어는 필수적임
- 모델 예측 제어(MPC, Model Predictive Control)는 온실 기후 제어에 일반적으로 사용 방식임
- 그러나 최근에는 강화 학습(RL, Reinforcement Learning)이 더 많은 주목을 받고 있음
- 따라서 본 논문은
- 통일된 프레임워크에서 온실 기후 제어를 위한 MPC 및 RL 접근법 제안
- 수학적 관점에서 MPC와 RL 간의 연결과 차이 분석
- 시뮬레이션 연구에서 MPC와 RL의 성능을 비교한 뒤 결과를 해석하여 다양한 시나리오에서 다른 제어 접근법의 응용에 대한 통찰력을 제공할 것임
INTRO
- MPC는 좋은 성능을 보이기 때문에 온실 시스템을 최적화하는 데 효과적임
- 그러나 예측 지표에서 발생하는 변동을 예측하는 것은 여전히 어려운 과제임
- RL은 환경(시스템)과의 시행착오 상호작용을 통해 제어 문제를 해결하는 알고리즘 및 기술의 모음으로, 온실의 기후 제어 모델 및 전략은 식물의 개발 단계 및 다양한 품종에 대해 업데이트 및 적응 가능함. RL은 최적 및 자율 온실 기후 제어의 선택지로서 점점 더 인기를 얻고 있습니다.
- 따라서 본 논문의 목적은 온실 기후 제어 환경에서의 MPC 및 RL의 개발과 적용을 비교하는 것임
Lettuce Greenhouse Model(상추 온실 모델)
- 상추 온실 모델은 선행 연구(E. J. van Henten, Greenhouse climate management: an optimal control approach, Ph.D. thesis, University Wageningen (1994))에서 가져온 것이고, 표본 기간이 h인 명시적 4차 Runge-Kutta 방법을 사용하여 이산화되었음

- 시간 : k / 파라미터 : p / 비선형 함수 : f
- 실제 값(상태) : x
- 상추를 뽑은 후 면적당 상추 무게 (x1)
- 실내 CO2 농도 (x2)
- 실내 공기 온도 (x3)
- 실내 습도 (x4)
- 예측 값 : y
- 상추를 뽑은 후 면적당 상추 무게 (y1)
- CO2 농도 (y2)
- 공기 온도 (y3)
- 습도 (y4)
- 제어 입력 : u
- CO2 공급 (u1)
- 환풍기 (u2)
- 난방 (u3)
- 날씨 요소 : d
- 일사량 (d1)
- 외부 CO2 농도 (d2)
- 외부 공기 온도 (d3)
- 외부 습도 (d4)
MPC vs RL
- 모델 예측 제어와 강화 학습은 각각 상호 독립적으로 발전해 왔음
- 모델 기반과 학습 기반 제어 방법의 대표적인 예인 MPC와 RL은 용어 사용부터 최적 제어 행동을 찾는 방식에 이르기까지 다르게 작동함
- MPC의 다양한 조건에 대한 범용성은 제한적이며 온실 생산에서의 목표에는 충분하지 않을 수 있음
- 강화 학습은 현재의 제어 정책을 자동으로 업데이트할 수 있는 동적 제어 전략으로, 역사적 및 실시간 데이터에서 학습한 새로운 지식을 통합함으로써 현재의 제어 정책을 개선할 수 있음
Nonlinear Model Predictive Control
1. 예측 원리
- MPC는 시스템의 모델을 사용하여 미래의 행동을 예측하고, 유한한 시간 지평 내에서 비용 함수를 최소화하는 최적의 제어 입력을 선택함. MPC는 시스템 상태와 입력에 대한 제약 조건을 처리할 수 있으며, 변화하는 조건과 불확실성에 적응할 수 있음
2. 최적화 원리

3. 비용함수와 제약조건

- 여기서 qy1 및 quj는 최적화에서의 가중치로 정의되며 튜닝할 수 있는 변수임. 이 비용 함수는 제곱 미터당 수율을 극대화하고 에너지 사용량(제어 입력)을 최소화하는 사이의 균형을 설정함
- 이 균형은 qy1과 quj의 비율에 의해 결정됨
Deep Reinforcement Learning
- Deep Deterministic Policy Gradient(DDPG) 알고리즘은 RL 제어 agent(학습 대상)를 개발하는 데 사용됨. DDPG의 장점은 대규모 및 연속적인 상태-행동 공간 환경에서 우수한 성능을 제공한다는 것임
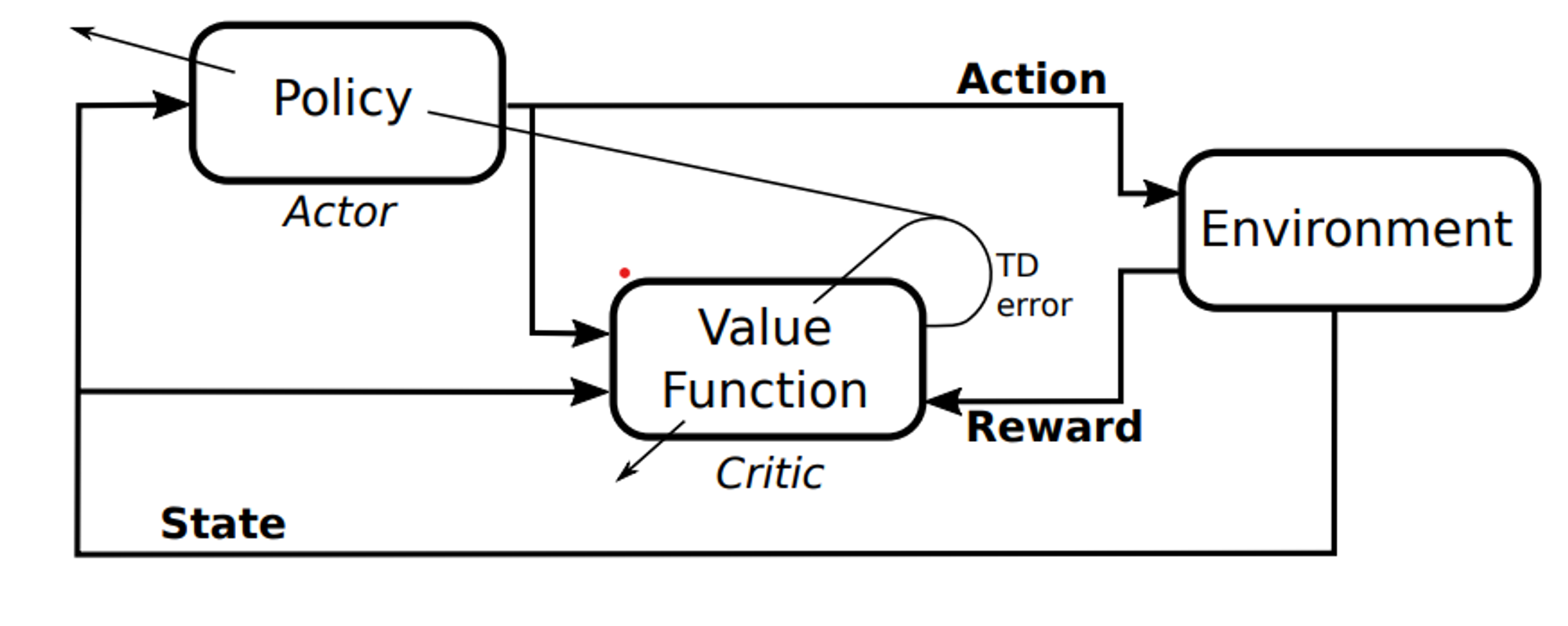
- DDPG는 off-policy 및 model-free actor-critic 강화 학습 알고리즘임
- policy : agent가 action을 선택하는 데 사용하는 규칙 → 어떤 state에서 어떤 action을 선택할 확률
- Model Free : Model(Environment)을 사용하지 않고 학습하는 방법 → Environment를 모르니 탐험을 통해 Policy를 점차 학습 시킴
- Actor-Critic 알고리즘 : action을 선택하는 actor-network와 그 action의 가치(보상)를 평가하는 critic-network로 구성
- Actor-critic RL 에이전트의 구조는 그림 3에 나와 있음. 여기서 actor는 현재 최상의 방안을 저장하고 적용하는 역할을 하며, 이를 위해 뉴럴넷을 사용함
- 학습된 방안 함수 π(s)와 시스템 상태 s에 따라 actor는 최적의 동작 u를 계산함
- 반면에 critic은 뉴럴넷을 사용하여 value 함수 Q(s, u)를 저장하는 역할을 함
- value 함수는 각 상태(s)-동작(u) 쌍에 대해 예상되는 reward임. critic은 시스템(환경)으로부터 얻은 reward 및 자체 정보를 사용하여 value 함수를 추정. 또한 critic은 학습 과정에서 critic과 actor 양쪽 모두에 대한 temporal-difference 에러(즉, 손실 함수)를 계산하는 역할을 담당함
Simulation Results
- 수집된 데이터 포인트는 5분 간격으로 샘플링 되었으며 이 중 N개가 선택되어 샘플 주기 h로 재샘플링되었음. 이는 288개의 샘플에 해당하며 이는 3일에 해당함
1. Economic Profit Indicator(경제적 이익 지표)
- 실내 CO2 농도, 기온, 상대 습도 등이 비용(보상) 함수에 최적화되어 있으며, 경제적 이익 지표(EPI)도 추가하였음
2. Specific MPC settings
- 가중치 qyˆ1, qui는 수확과 에너지 사용 간의 적절한 균형을 달성하기 위해 조정됨
- 예측 호리즌 Np는 시간이 지남에 따라 커지는 불확실성을 포함해야 하는 필요성을 방지하기 위해 너무 크지 않게 선택됨. 실제로 날씨 예측은 미래에 걸쳐 더 불확실해짐. 시뮬레이션 연구 중 사용된 기타 설정은 표 4에 나와 있음
3. Results

- Figure 6에서는 DDPG 기반 RL 에이전트(파란색)와 MPC 컨트롤러(주황색)를 사용한 시뮬레이션 온실의 측정 결과를 보여줌. MPC와 RL 모두 상추의 무게는 유사하지만 RL이 약간 더 생산적임
- 다른 출력은 대략적으로 제약 내에 유지됨. 내부 상대 습도 수준은 두 경우 모두 매우 유사하지만 RL은 더 많은 변동을 허용함
- 마찬가지로, 온실 내 온도와 이산화탄소 농도는 최소 수준에 가깝지만 RL 에이전트는 온도를 최소 온도보다 약간 높은 수준으로 유지하여 이 패널티를 피함
- RL 에이전트는 최소 온도 제약 조건을 위반할 때 비용 함수가 처벌하기 때문에 명확하게 MPC보다 보수적임. MPC 컨트롤러는 습도를 더 정확하게 제어하지만 DDPG 에이전트는 실내 온도에 더 잘 대응함
- 이산화탄소 농도는 두 컨트롤러 모두에서 주간에 상당히 증가하는 것으로 예상되지만, DDPG 에이전트는 밤에도 더 높게 유지됨
- Figure 7은 두 컨트롤러의 제어 액션을 보여줌. MPC가 더 효율적으로 환기를 사용하지만, DDPG 에이전트는 더 많은 양의 에너지를 공급함
- 생산 측면에서 RL 에이전트는 상추의 더 큰 생산량을 달성하지만, 경제적 이익 측면에서 MPC는 에이전트보다 높은 경제적 수익을 달성함
- 이는 상추 생산 증가의 경제적 수익이 경제적 반환 함수에 매개 변수로 주어진 경우 자원 소비 비용보다 낮기 때문임. Figure 7에서 온도 수준은 두 경우 모두 낮게 유지되지만 RL 에이전트는 CO2 농도를 MPC보다 훨씬 높은 수준으로 유지함. 이러한 행동에 대한 설명은 CO2 주입의 증가가 생산을 크게 증가시킬 수 있기 때문에 에이전트가 이 옵션을 탐험하는 데 선호되었으며 이로 인해 최적의 솔루션에 도달하지 못했을 수 있음

- Figure 8은 상추의 완전한 성장 주기에 대한 시뮬레이션 된 온실의 출력을 보여줌. RL의 생산량은 현재 분명히 더 높지만 EPI는 더 작음. 또한 RL 에이전트가 습도 제한에 대해 더 관대한 것으로 나타남. 이것은 작물에 대한 건강 문제가 될 수 있으며 주의 깊게 살펴봐야 할 사항임
Discussion and Conclusion
Model Predictive Control (MPC)과 Reinforcement Learning (RL)의 장단점
모델 예측 제어 (MPC)강화 학습 (RL)
| 좋은 모델에 의지하라 | 모델 프리일 수 있음 |
| 2차 볼록 모델에서 최적화 | 의사결정을 위한 학습 |
| 제약조건을 쉽게 처리 | 제약사항을 처리하기가 어려움 |
| 장기 예측과의 싸움 | 무한한 예측 범위 |
| 불확실성에 대한 높은 계산 부하 필요 | 본질적인 견고성 |
| 낮은 적응성 | 높은 적응성 |
| 온라인 최적화 복잡성이 높음 | 온라인 학습의 복잡성이 낮음 |
궁금한 점이 있으시면 댓글이나 이메일로 문의해 주세요. 확인하는 대로 답변드리겠습니다.